Spark Streaming를 통해 Kafka에서 메세지를 읽어 HDFS에 저장하는 작업중에, 카프카 메세지가 중복으로 저장되는 이슈가 있어 원인 및 해결책을 알아보았다.
1. 상황
Kafka에서 HDFS에 파일로 저장한 후 CanCommitOffsets.commitAsync 를 이용하여 offset을 커밋중이다.

상단의 이미지는 Spark Streaming Kafka Integration의 Storing Offsets 부분이다.
2. 현상
Spark Streaming 잡을 종료 시킨뒤 다시 재시작하면 동일한 메세지가 중복되어 컨슈밍 된다.
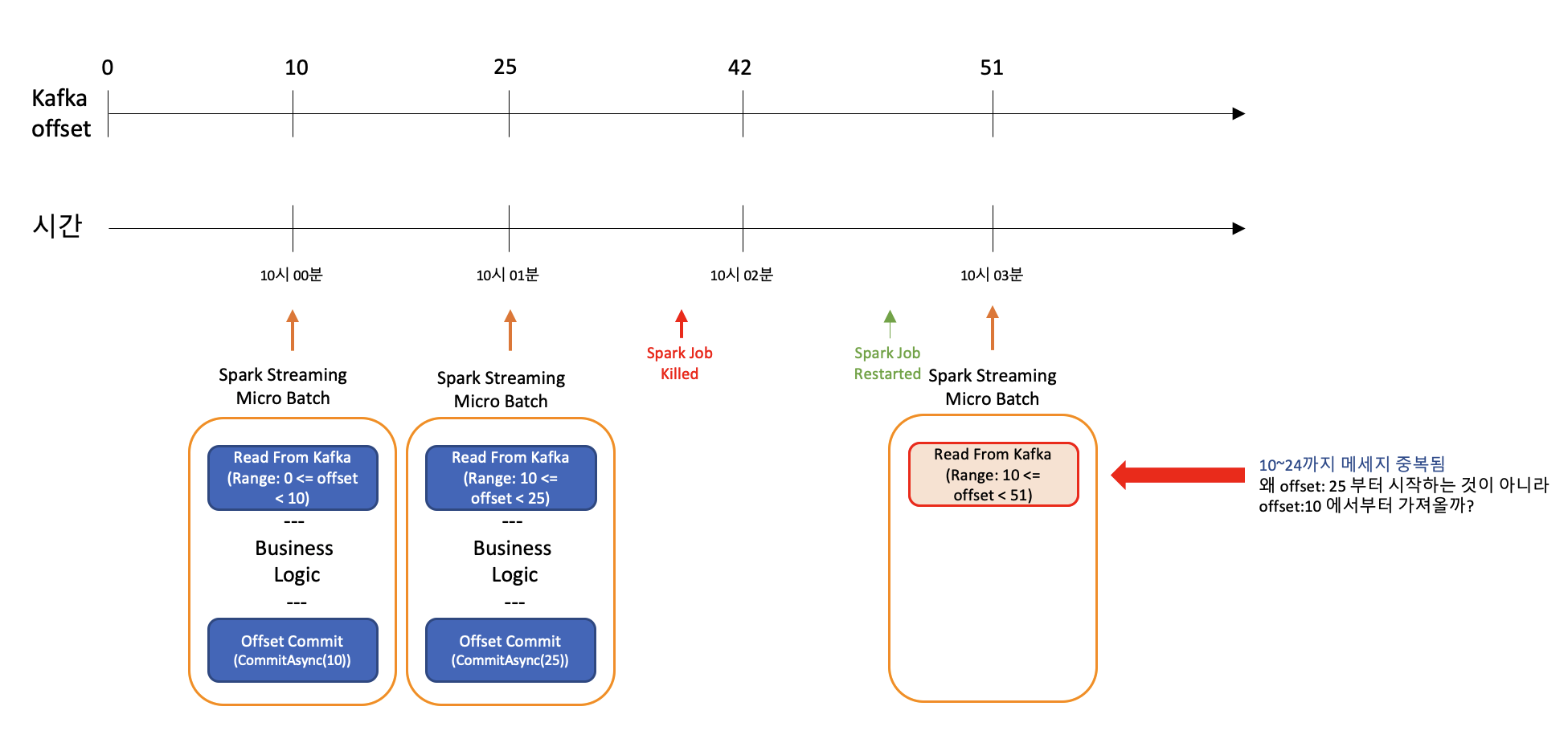
그림에서 보는것과 같이 3번 마이크로 배치 수행시 offset:25~51의 데이터를 가져오는 것이 아니라 offset:10~51의 데이터를 가져오게 됨으로서 offset:10~24까지 메세지가 중복이 되게 된다.
3. 원인 분석
메소드 이름에서도 느껴지듯, CanCommitOffsets.commitAsync 메소드는 메소드 호출 즉시 offset을 커밋하지 않는다. 내부적으로 commitQueue로 정의된 ConcurrentLinkedQueue에 저장하면서 끝난다.
/*
https://github.com/apache/spark/blob/master/external/kafka-0-10/src/main/scala/org/apache/spark/streaming/kafka010/DirectKafkaInputDStream.scala#L281
*/
/**
* Queue up offset ranges for commit to Kafka at a future time. Threadsafe.
* @param offsetRanges The maximum untilOffset for a given partition will be used at commit.
*/
def commitAsync(offsetRanges: Array[OffsetRange]): Unit = {
commitAsync(offsetRanges, null)
}
/**
* Queue up offset ranges for commit to Kafka at a future time. Threadsafe.
* @param offsetRanges The maximum untilOffset for a given partition will be used at commit.
* @param callback Only the most recently provided callback will be used at commit.
*/
def commitAsync(offsetRanges: Array[OffsetRange], callback: OffsetCommitCallback): Unit = {
commitCallback.set(callback)
commitQueue.addAll(ju.Arrays.asList(offsetRanges: _*))
}그럼 commitQueue는 언제 읽힐까?
/*
https://github.com/apache/spark/blob/aea78d2c8cdf12f4978fa6a69107d096c07c6fec/external/kafka-0-10/src/main/scala/org/apache/spark/streaming/kafka010/DirectKafkaInputDStream.scala#L227
*/
override def compute(validTime: Time): Option[KafkaRDD[K, V]] = {
val untilOffsets = clamp(latestOffsets())
val offsetRanges = untilOffsets.map { case (tp, uo) =>
val fo = currentOffsets(tp)
OffsetRange(tp.topic, tp.partition, fo, uo)
}
val useConsumerCache = context.conf.get(CONSUMER_CACHE_ENABLED)
val rdd = new KafkaRDD[K, V](context.sparkContext, executorKafkaParams, offsetRanges.toArray,
getPreferredHosts, useConsumerCache)
// Report the record number and metadata of this batch interval to InputInfoTracker.
val description = offsetRanges.filter { offsetRange =>
// Don't display empty ranges.
offsetRange.fromOffset != offsetRange.untilOffset
}.toSeq.sortBy(-_.count()).map { offsetRange =>
s"topic: ${offsetRange.topic}\tpartition: ${offsetRange.partition}\t" +
s"offsets: ${offsetRange.fromOffset} to ${offsetRange.untilOffset}\t" +
s"count: ${offsetRange.count()}"
}.mkString("\n")
// Copy offsetRanges to immutable.List to prevent from being modified by the user
val metadata = Map(
"offsets" -> offsetRanges.toList,
StreamInputInfo.METADATA_KEY_DESCRIPTION -> description)
val inputInfo = StreamInputInfo(id, rdd.count, metadata)
ssc.scheduler.inputInfoTracker.reportInfo(validTime, inputInfo)
currentOffsets = untilOffsets
commitAll()
Some(rdd)
}
protected def commitAll(): Unit = {
val m = new ju.HashMap[TopicPartition, OffsetAndMetadata]()
var osr = commitQueue.poll()
while (null != osr) {
val tp = osr.topicPartition
val x = m.get(tp)
val offset = if (null == x) { osr.untilOffset } else { Math.max(x.offset, osr.untilOffset) }
m.put(tp, new OffsetAndMetadata(offset))
osr = commitQueue.poll()
}
if (!m.isEmpty) {
consumer.commitAsync(m, commitCallback.get)
}
}
compute라는 메소드가 호출되면 Kafka에서 메세지를 컨슈밍 하고, 마지막으로 commitAll을 호출하여 실제로 카프카 offset이 커밋이 되게 된다.
즉.

이런 방식으로 진행되며, 1번 마이크로 배치의 offset은 2번 마이크로 배치의 메세지 읽기가 끝난 후 커밋 되는 것을 확인 할 수 있다.
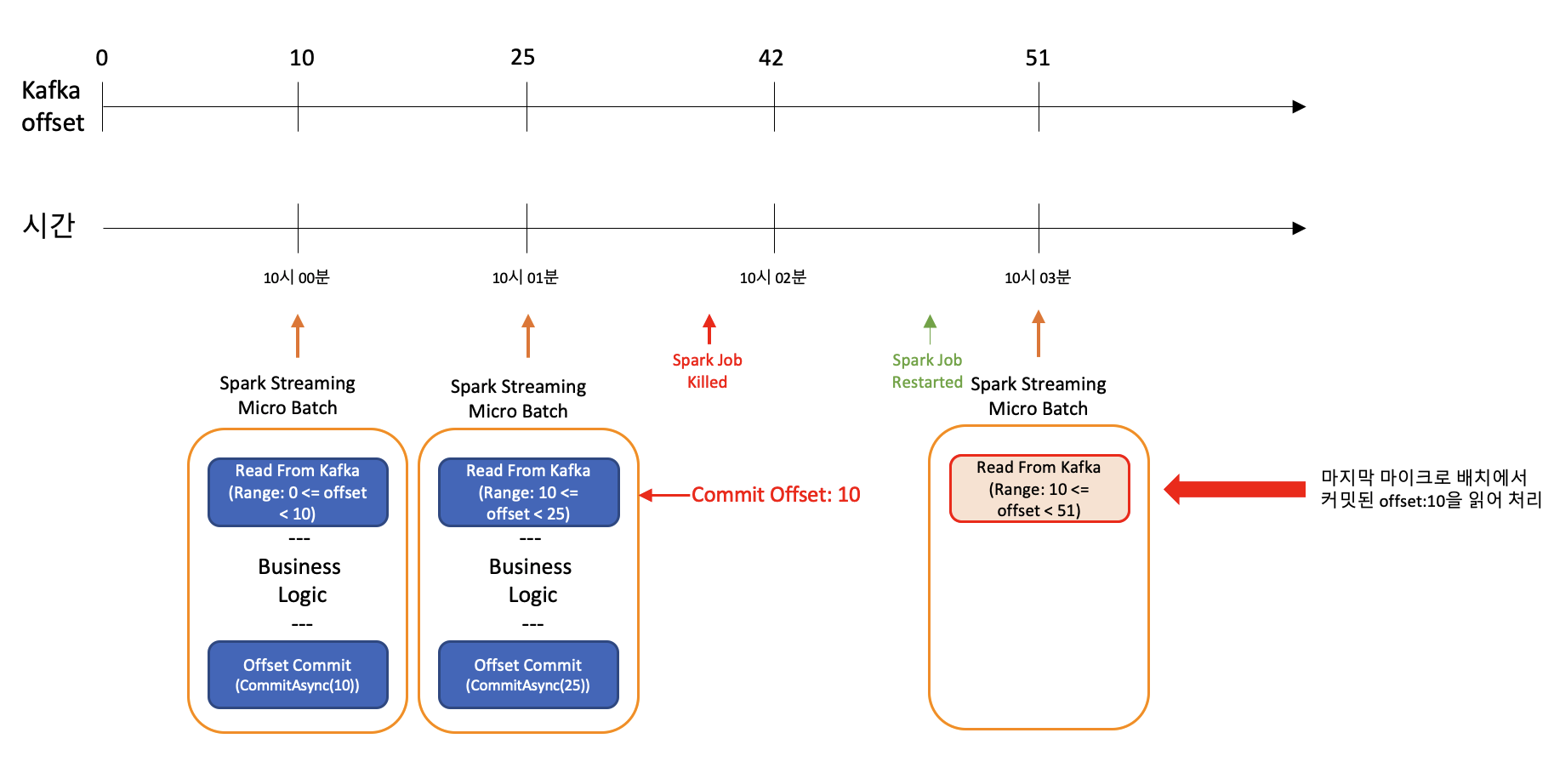
위의 이미지와 같이 2번 마이크로 배치에서 1번 마이크로 배치의 offset이 커밋 되었기 때문에 종료후 재시작된 마이크로 배치 3에서는 offset:10 부터 읽게 되는것이다.
4. 궁금점?
위의 내용대로라면, 마이크로 배치가 수행될 때마다 중복으로 데이터가 저장이 되어야 하는데, 실제로는 스트리밍 프로세스가 내려가지 않는한 중복없이 컨슈밍이 된다. 왜 그럴까?
spark streaming 설정중 spark.streaming.kafka.consumer.cache.enabled의 값이 있는데, 이는 매번 카프카의 offset을 저장소에서 읽어오는 것이 아니라, 메모리에 캐싱한 후 Spark Streaming 프로세서가 정상적으로 동작하면 캐시에서 값을 불러와 사용하기 때문에, 연속적으로 처리되는 마이크로 배치에서는 중복이 발생하지 않는다.
참고로 해당 옵션은 기본값이 true 이기 때문에, 자동으로 offset이 캐시에 저장이 되도록 되어있다.
5. 해결책
해결책은 제3의 저장소( Zookeeper, HBase, HDFS, Redis etc... )에 offset을 저장하는 방식으로 처리하면 된다.
관련한 내용은 다음 포스팅에서 작성해보겠다.
다음 포스팅: [Spark Streaming] Streaming 처리시 Offset을 저장해보자.
'OpenSource > Spark' 카테고리의 다른 글
| [Spark] SparkContext.addFile 과 --files 의 차이점 (Spark on YARN) (0) | 2021.06.25 |
|---|---|
| [Spark Streaming] Streaming 처리시 Offset을 저장해보자. (0) | 2021.04.15 |
| [Spark] HDFS 하위 경로의 모든 파일 읽기(with Java) (0) | 2020.04.27 |
