
Apache Kudu 는 Columnar Storage로서, 실시간/대용량 데이터 분석이 가능한 저장 엔진이다. 여기에 Impala, Spark를 이용하여 쉽고 빠른 데이터 분석이 가능한 특징이 있다.
1. Kudu의 장점
- OLAP성 작업의 빠른 처리
- MapReduce, Spark 및 기타 Hadoop 에코 시스템 컴포넌트들과의 통합
- Apache Impala와의 강력한 통합으로 Apache Parquet와 함께 HDFS를 사용하는 것보다 좋은 대안이 될수 있다.
- 강력하지만 유연한 일관성 모델을 통해 엄격한 직렬화 가능 일관성 옵션을 포함하여 요청별로 일관성 요구 사항을 선택할 수 있다.
- 순차적 및 랜덤 워크로드를 동시에 실행하기위한 강력한 성능.
- 관리가 쉬움
- 높은 가용성. 태블릿 서버와 마스터 서버는 Raft Consensus Algorithm을 사용하여 HA를 구성
- 리더 태블릿의 오류가 발생하더라도 읽기 전용 팔로어 태블릿을 통해 읽기 서비스를 제공 가능함
- 구조화 된 데이터 모델
2. Kudu의 구성요소
-
Table : 테이블은 데이터가 저장되는 장소이다. 테이블은 스키마와 전체적으로 정렬되어 있는 Primary key를 가지고 있다. 테이블은
tablet이라고 불리는 세그먼트로 나뉘어 질 수 있다. -
Tablet : 태블릿은 다른 데이터 저장 엔진이나 관계형 데이터베이스의 파티션과 유사한 테이블의 연속적인 부분이다. 주어진 태블릿은 여러 개의 태블릿 서버에 복제되며, 주어진 시점에 이러한 복제품 중 하나가 리더 태블릿으로 간주된다. HBase의 Region과 유사함
-
Tablet Server : 태블릿 서버는 태블릿을 저장하고, 클라이언트에게 데이터를 제공한다. HBase의 Region Server와 유사함
-
Master : 마스터는 모든 카탈로그 테이블이라고 불리우는 태블릿과 태블릿 서버 메타 데이터와 클러스터 메타 데이터를 저장한다. Tablet과 마찬가지로 Raft Consensus Algorithm을 이용해 Master중 리더가 선출되며 선출된 마스터를 통해 메타데이터를 읽거나 쓸수 있다.
3. Kudu Architecture
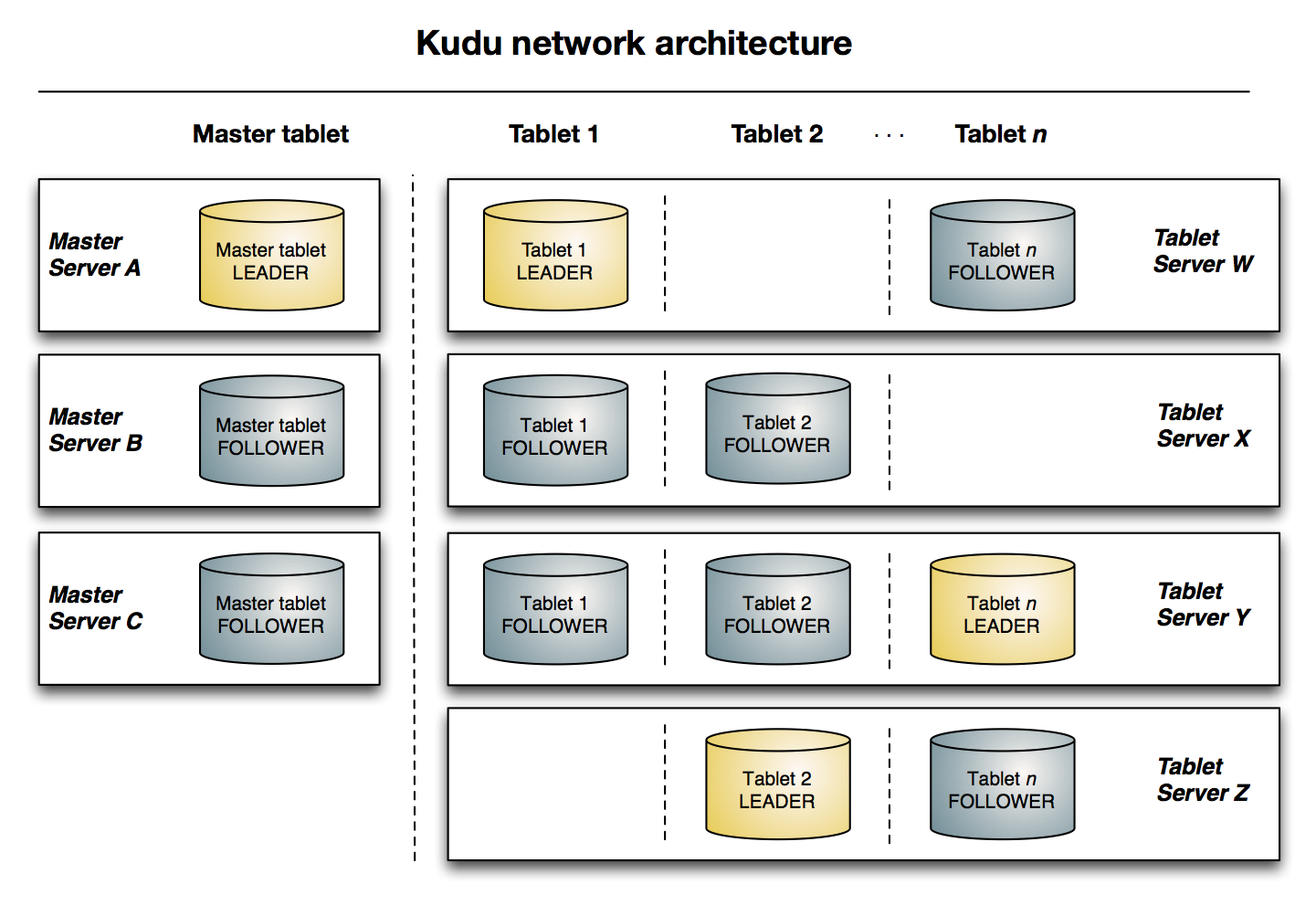
위의 구성요소에서 설명한데로 Master와 Tablet은 하나의 마스터와 여러개의 Follow를 가지며, Replication 구성된 태블릿은 여러대의 Table Server에 분산 저장 되는것을 볼수 있다.
출처: https://kudu.apache.org/docs/
'Hadoop > Kudu' 카테고리의 다른 글
| [Kudu]Kudu와 Presto 그리고 unix_timestamp에 대해 이해하기 (0) | 2020.03.09 |
|---|---|
| [Kudu] 시간 기준의 Range Partition 시 주의점(timezone, UTC) (0) | 2020.02.12 |
| [Kudu] Encoding & Compression (0) | 2020.02.12 |
| [Kudu] Source 를 이용한 설치 (0) | 2020.02.12 |
| [Kudu] Write And Compaction (0) | 2020.02.12 |


