Nifi 1.8.0 버전부터 Load Balance라는 기능이 생겼다. (자세한 설명은 여기로)
말그대로 flowfile을 적당한 기준에 맞춰 각 노드들로 분산을 시켜준다는것인데, 직관적인 이름이기 때문에 이해하기 어렵지 않다.
1. Load Balance 종류
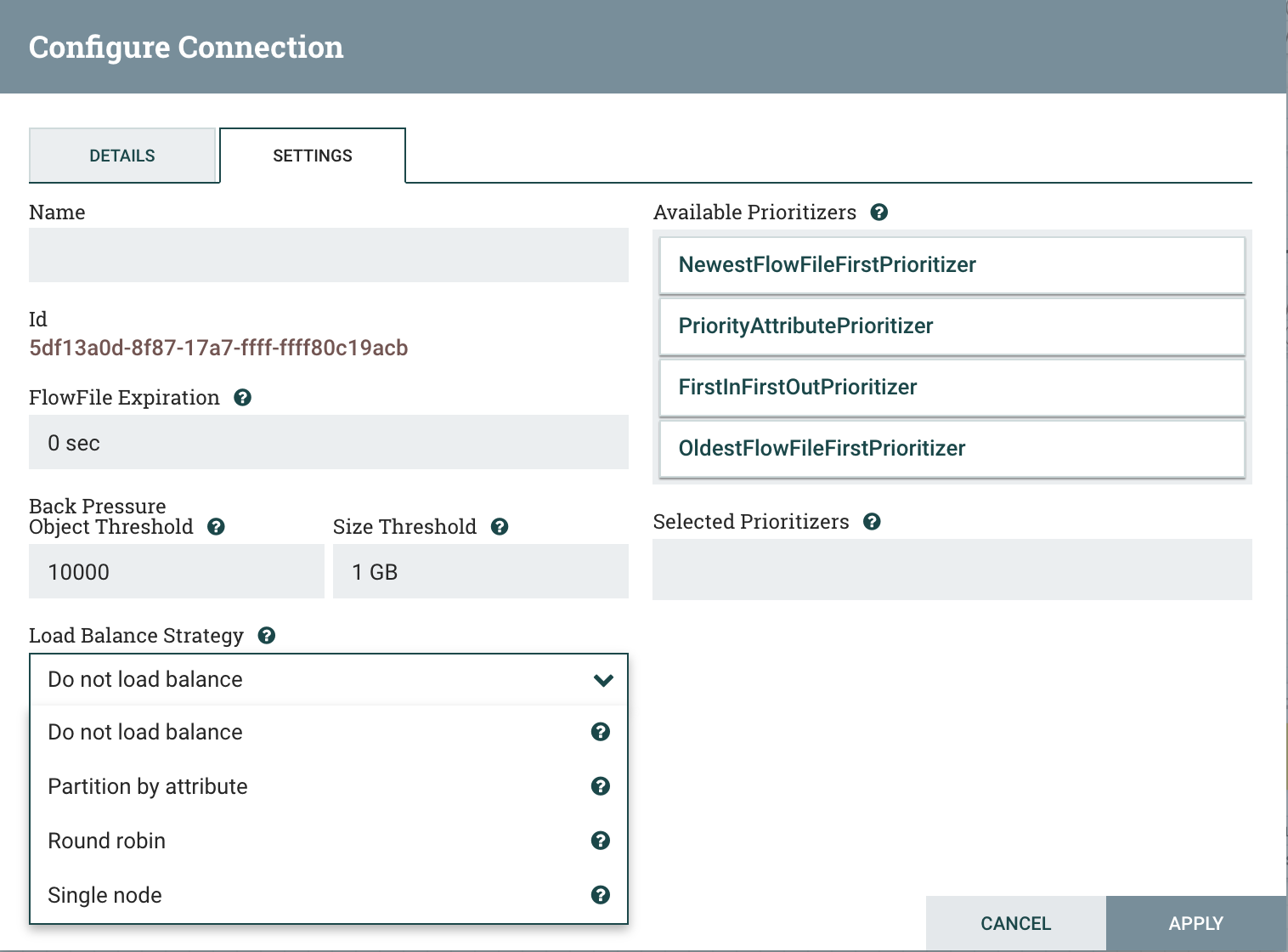
- Do Not load balance(기본값): 로드 밸런스를 사용하지 않음
- Partition by attribute : Flowfile의 특정 attribute를 통해서 로드 밸런싱 함
- Round robin: Nifi 클러스터를 구성하는 노드에 순차적으로 분산시킴
- Single Node: 하나의 Nifi 노드로만 보냄
테스트
- 클러스터 : 3 Nodes

- GenerateFlowFile(Primary Node Only) : 테스트용 Flowfile 생성
- UpdateAttribute(Primary Node Only) : partition.key라는 Attribute를 생성하고 Modular 연산을 통해 0~2까지의 값이 나오도록 설정

- LogAttribute(All Nodes) : 전달받은 Flowfile의 Attribute를 로그로 출력
UpdateAttribute -> LogAttribute 사이의 Queue는 아래와 같이 설정
특이점 발견
이상하게도 3개의 노드중 2번과 3번 노드로만 Flowfile 분산된다.

일반적으로 Bucket(여기에는 노드 수)이 3이고 모듈러 연산을 통한 값이 0,1,2 라면 모두 다른 노드로 분산되어야 정상인데, 실제 flowfile을 열어보면 partition.key가 1이면 3번 노드로, partition.key가 2,3이면 2번노드로 flowfile을 전송한다.
원인은?
Partition By Attribute를 수행하는 클래스인 CorrelationAttributePartitioner을 열어보자.
//https://github.com/apache/nifi/blob/master/nifi-nar-bundles/nifi-framework-bundle/nifi-framework/nifi-framework-core/src/main/java/org/apache/nifi/controller/queue/clustered/partition/CorrelationAttributePartitioner.java
public class CorrelationAttributePartitioner implements FlowFilePartitioner {
...
@Override
public QueuePartition getPartition(final FlowFileRecord flowFile, final QueuePartition[] partitions, final QueuePartition localPartition) {
final int hash = hash(flowFile);
// The consistentHash method appears to always return a bucket of '1' if there are 2 possible buckets,
// so in this case we will just use modulo division to avoid this. I suspect this is a bug with the Guava
// implementation, but it's not clear at this point.
final int index;
if (partitions.length < 3) { //<== 이부분이 핵심
index = Math.floorMod(hash, partitions.length);
} else {
index = Hashing.consistentHash(hash, partitions.length);
}
if (logger.isDebugEnabled()) {
final List<String> partitionDescriptions = new ArrayList<>(partitions.length);
for (final QueuePartition partition : partitions) {
partitionDescriptions.add(partition.getSwapPartitionName());
}
logger.debug("Assigning Partition {} to {} based on {}", index, flowFile.getAttribute(CoreAttributes.UUID.key()), partitionDescriptions);
}
return partitions[index];
}
}코드의 partitions는 Nifi Cluster를 구성하는 Node 정보 배열이다. 즉 클러스터를 구성하는 노드가 3보다 작으면 Math.floorMod(hash, partitions.length) 이 코드를, 그 이상이면 Hashing.consistentHash(hash, partitions.length) 을 통해 파티션을 선택한다.
이렇게 노드의 갯수에 따라 partition index를 구하는 방식이 달라지는데, 이는 주석에도 잘 나와있다.
// The consistentHash method appears to always return a bucket of '1' if there are 2 possible buckets,
// so in this case we will just use modulo division to avoid this. I suspect this is a bug with the Guava
// implementation, but it's not clear at this point.결과적으로 현재 클러스터의 노드는 3개임으로 index = Hashing.consistentHash(hash, partitions.length); 이 코드가 수행되는것을 확인할 수 있다.
Consistent Hashing(일관된 해싱)은?
위의 Hashing 클래스는 Guava 라이브러리에 포함되어있는 클래스이다.
그렇다면 Consistent Hasing은 무엇일까?
간단하게 설명하자면 데이터를 나눠가지는 노드의 수가 변경(추가/제거) 되어도, 모든 값을 재정렬하지 않고 일부 데이터만 데이터를 나눠가지면 되는 해시 알고리즘 이라고 한다.(사실 나도 이번에 알게되었다)
즉 Consistent Hashing을 쓰기 때문에 모듈러 연산의 값 = Nifi 노드 가 아니었던 것이다. 따라서 Nifi의 Load Balance는 정상적인 상황으로 결론이 났다.
결론
만약 Partition by Attribute Load Balance를 의도한대로 분산하고자 한다면 Attribute는 작은 범위의 값이 반복적으로 나오기 보다는 넓은 범위의 값이 나오도록 설정해야한다.
'OpenSource > Nifi' 카테고리의 다른 글
| [Nifi] Flowfile 순서보장 삽질기 (0) | 2020.05.11 |
|---|---|
| [Nifi] Flowfile 중복제거를 위한 DetectDuplicate 사용 및 주의점 (0) | 2020.04.30 |
| [Nifi]Could Not Generate Extensions Documentation 에러 해결 방법 (0) | 2020.02.12 |
| [Nifi] Custom Processor 생성 및 테스트 (0) | 2020.02.12 |


