필자는 커스텀 프로세서를 통해 DB에서 특정 시간컬럼을 기준으로 데이터를 크롤링하고, 실시간 반영을 위하여 kafka로 전송하는 것을 Nifi를 통해 구현하였다.
이때 내부적 이슈에 의해 DB에서 데이터를 검색하는 쿼리에서 누락이 발생했고, 이를 해결하기 위하여 마지막 동작시간 - 10초 전 데이터를 더 가지고 오도록 함으로서 누락 문제를 해결하였으나, 추가적으로 데이터의 중복이라는 문제를 해결해야 하는 이슈가 있었다.
이번에는 flowfile 중복을 해결할수 있는 DetectDuplicate를 사용하는 방법과 주의할 점에 대해서 이야기 해보도록 하려고 한다.
1. DetectDuplicate의 기본컨셉
DetectDuplicate는 flowfile contents의 hash값을 통하여 기존에 캐시에 존재하는 값인지 아닌지를 판단하여 중복이라면 duplicate로 아니라면 non-duplicate relationship으로 보내는 역할을 한다.
필자는 커스텀 오퍼레이터를 직접 구현하였기 때문에 각 flowfile에 attribute에 hash.value라는 attribute를 추가하였고, 이 attribute에는 SHA-256 방식으로 컨텐츠를 해시값으로 변경하여 저장하였다.
만약 필자와 같이 커스텀오퍼레이터를 사용하지 않는다면 CryptographicHashContent를 이용하여 flowfile 컨텐츠를 해시값으로 변환한 후 이를 DetectDuplicate에 연결하여 사용하면 되겠다.
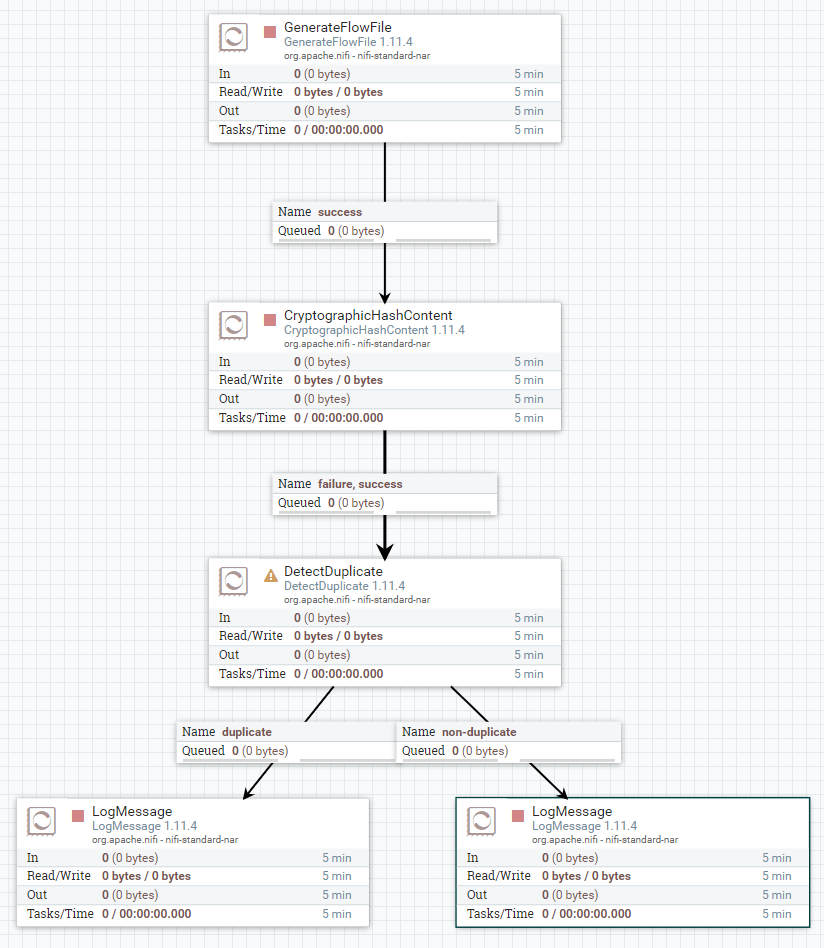
2. DetectDuplicate의 설정

- Cache Entry Identifier: flowfile에서 중복체크의 키가 될 Attribute
- FlowFile Description: 중복이라고 판된된 flowfile에
original.flowfile.description라는 이름의 attribute가 추가되는데, 이때 이 attribute에 추가할 값을 설정. 필자는 원본 flowfile의 filename attribute를 지정하도록 하여 문제 발생시 쉽게 원본과 중복 데이터를 찾도록 하기 위함 - Age Off Duration: 중복의 기준이 될 시간, 동일한 데이터가
Age Off Duration에 설정한 시간안에 DetectDuplcate 프로세서에서 처리된다면 중복으로, 이 시간이 지난후 처리된다면 중복아님으로 처리 - Distributed Cache Service: 다양한 Cache 솔루션을 사용하여 저장함, 필자는 Redis를 이용
- Cache The Entry Identifier: 중복 확인후 엔트리 식별자를
Distributed Cache Service에 지정된 캐시에 저장할지 말지를 결정함.
3. 구현방식
구현방식은 간단하다. Cache Entry Identifier에 설정한 값을 key로 하여, Cache Service에 지정한 솔루션에 데이터를 저장한다.
이때 저장형식은
key => Processor 설정의 Cache Entry Identifier
value => Processor 설정의 FlowFile Description, 현재 Unix time
으로 저장된다.
그리고 이 데이터를 캐시 서비스에 저장하고, 다음에 들어오는 flowfile의 Cache Entry Identifier값을 캐시 서비스에서 검색하여
1) 동일한 해시값을 가진 키가 캐시 서비스에 존재하고 AND
2) 프로세서에 인입된 flowfile의 현재 시간과, 캐시 서비스에 존재하는 value의 Unix time + Age Off Duration의 값과 작거나 같다면
(즉 Age Off Duration에 지정된 시간안에 중복 데이터가 인입되었다면)
==> 중복
의 로직으로 중복여부를 체크한다. 실제 로직은 여기 에서 확인할 수 있다.
3. 사용상 주의점
초기에 Age Off Duration 설정값이 Redis의 expire time으로 생각했다. 왜냐하면 캐싱된 flowfile content의 hash값에 expire time을 걸어 두고 flowfile을 체크할때 해시값의 키를 가진 데이터가 있으면 중복, 없으면 중복아님으로 체크하면 될것이라고 생각했다.
하지만 실제 코드를 열어보면 expire 설정하는 부분이 없는데, 이것을 가만히 생각해보면 충분히 이해가 되는부분이다.
추측1: Expire를 이용하여 구현하지 않은 이유
Distributed Cache Service 항목에 사용할수 있는 서비스들은 CouchDB, DistributedMap, Hbase, Redis를 지원하는데(1.11.4 버전 기준), 이 모든 솔루션들이 expire를 지원하는것이 아니기 때문에 솔루션들마다 로직을 분기하여 작성하기 보다는 일관된 로직을 적용하는것이 낫다고 판단한듯하다.
추측2: Expire를 이용하여 구현하지 않은 이유
만약 모든 솔루션들이 expire를 사용할수 있다고 하더라도, 구현방식에 따라 expire를 설정한 시간에 정확하게 삭제가 될수도, 되지 않을수도 있다. 이 때문에 중복체크가 부정확하게 동작할수 있음으로 현재의 구현식방이 더 나은 방식이다.
위와 같은이유로 expire 를 사용하지 않았다고 유추할수 있는데, expire를 사용함으로서 로직의 일관성, 로직의 정확성을 구현할수 있는 대신 캐싱된 데이터가 한번 캐싱되면 삭제되지 않는다는 문제점도 가지고 있다.
즉
DetectDuplicate 프로세서는 캐시 서비스에 put/get만 할뿐 캐싱된 데이터를 삭제하지 않아, 캐시데이터를 주기적으로 삭제하거나, 캐시가 가득 찼을때 이슈가 발생하지 않도록 미리 계획을 세워야 한다.
필자는 레디스를 캐시서비스로 사용하고 있기 때문에, 위의 이슈를 해결하기 위한 레디스 설정을 공유해본다
- Maxmemory 설정
- Eviction policy 설정
첫번째 maxmemory는 레디스에서 사용하고자 하는 메모리의 최대값을 설정함으로서, 물리적으로 서버에 설치된 메모리 이상 사용하지 않도록 설정하는것이고, 두번째 Eviction policy는 메모리가 가득 찼을때 어떤 데이터부터 삭제를 할것이냐에 대한 정책이다.
이때 주의할점은 Eviction Policy를 설정할때 noneviction값을 지정하게 되면 메모리가 가득 차더라도 삭제되지 않고, 에러를 발생시키는 옵션임으로 allkey-lru를 설정하도록 하자.
레디스 설정관련 내용이 더 궁금하시면 Using Redis as an LRU cache 를 참고하도록 하자
2020.06.10 추가사항
존재하지 않는것 처럼 보였던 Redis의 expire time 설정을 찾게 되어 추가적으로 내용을 적어본다. DetectDuplicate를 사용하려면 RedisDistributedMapCacheClientService를 등록해야 하는데, 이 서비스안에 TTL 설정이 존재한다.

기본설정인 0인 상태로 있다면 Expire time을 설정하지 않고 그 이외의 수라면 expire time을 설정해 주니, Expire time 설정을 하고자 한다면 해당 서비스의 property를 수정하자.
'OpenSource > Nifi' 카테고리의 다른 글
| [Nifi] Flowfile 순서보장 삽질기 (0) | 2020.05.11 |
|---|---|
| [Nifi] Load Balance와 Partition by attribute 삽질기 (0) | 2020.04.27 |
| [Nifi]Could Not Generate Extensions Documentation 에러 해결 방법 (0) | 2020.02.12 |
| [Nifi] Custom Processor 생성 및 테스트 (0) | 2020.02.12 |


